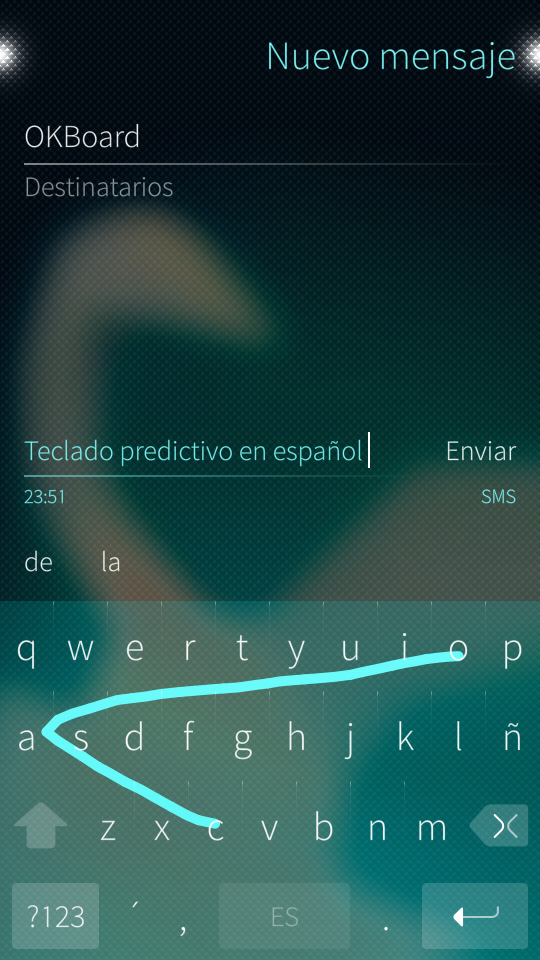
Spanish language for OKBoard
Spanish language resources for OKboard gesture based keyboard (dictionary & prediction data).
Created from balanced data resources like newspapers, novels, wikipedia & film subtitles.
Corpora's based on 4GB database source file.
Make sure you use the real "N" key and not "Ñ" to type words with that letter like "España" o "Coño".
Category:
| Attachment | Size | Date |
|---|---|---|
| 3.11 MB | 22/01/2016 - 15:27 | |
| 3.58 MB | 22/01/2016 - 16:35 | |
| 3.64 MB | 17/02/2016 - 19:36 | |
| 5.07 MB | 12/12/2016 - 21:20 | |
| 5.51 MB | 18/01/2017 - 15:08 | |
| 5.51 MB | 03/03/2017 - 18:00 | |
| 5.51 MB | 09/06/2021 - 17:52 |
* Wed Jun 09 2021 | Version 0.7-1:
- aarch64 & armv7 compatible
* Fri March 03 2017 | Version 0.6.9-1:
- Fully compatible with Okboard-full-0.6.9-1
https://openrepos.net/content/eber42/okboard
- Builded over DataBase 16 (https://git.tuxfamily.org/okboard/okb-engine.git/)
- Better Spanish text recognition
- Improved accuracy
- Corpora's based on 3,5GB database source files
* Wed Jan 18 2017 | Version 0.6-1:
- Fully compatible with Okboard-full-0.6-1
https://openrepos.net/content/eber42/okboard
- Builded over DataBase 16 (https://git.tuxfamily.org/okboard/okb-engine.git/)
- Much better Spanish text recognition.
- Highly improved accuracy
- Corpora's based on 3GB database source file.
* Mon Dec 12 2016 | Version 0.5.12-1:
- Fully compatible with Build of okbengine - Unofficial! (okboard-full-0.5.12-1)
https://openrepos.net/content/skyjumper/build-okbengine-unofficial
- Builded over DataBase 15 (https://git.tuxfamily.org/okboard/okb-engine.git/)
- Much better Spanish text recognition.
- Highly improved accuracy
- Corpora's based on 4GB database source file.
- Removed corpora from Tatoeba sentences.
* Wed Feb 17 2016 | Version 0.3-1:
- Better Spanish text recognition.
- Improve accurate.
- Corpora's based on 450MB database source file.
- Added corpora from OpenSubtitles.
* Wed Jan 22 2016 | 0.2-1
- Doubled the corpora size, including fonts from blogs and chats dumps.
- Corpora's based on 400MB database source file.
- Added corpora from the Universidad Autónoma de Madrid: Laboratorio de Lingüística Informática. Corpus (oral) de Referencia de la Lengua Española Contemporánea
- Added corpora from Tatoeba sentences.
*Thu Jan 21 2016 | Version 0.1-1:
- Corpora's first build based on 200MB database source file.
Laatste reacties